
Rewards and Acts based upon MDP (Dynamic Programming) [Sq - 7]
- Steven Willers
- Jan 17, 2024
- 2 min read

Andrey Andreyevich Markov a Russian Computer Scientist was known for his work on Markov Models , a basically computer chain which laid the foundation of A.G.I.(later known as AI) ; in the perspective of mine this is probably the oldest known work which is used now in the generative purpose of machine models . As well as Stochastic processes and various equations are known today by the contribution of Andrey Markov .
Policy(π) and Discount Factor(r)
Policy :
•The policy, denoted by π, represents the strategy or set of rules that an agent follows to make decisions in the environment.
• It defines the mapping from states to actions, indicating what action the agent should take in each state.
• A deterministic policy maps each state to a specific action, while a stochastic policy assigns probabilities to different actions in each state.
Discount Factor (r or γ):
•The discount factor, often denoted by "r" or "γ," is a value between 0 and 1 that determines the importance of future rewards in the decision-making process.
•It reflects the agent's preference for immediate rewards over delayed ones. A higher discount factor places more emphasis on immediate rewards.
• Discounting is crucial for handling the inherent uncertainty and variability in future outcomes.
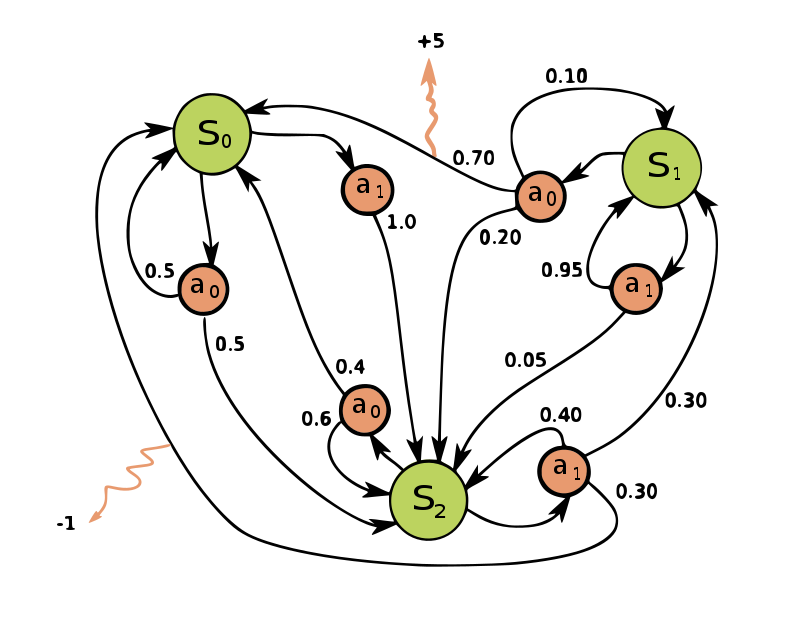
Rewards(R)
The (R) represents the immediate benefit or cost associated with taking a particular action in a specific state.
It is the value obtained by the agent when it transitions from one state to another by taking a specific action.
Unlike the discount factor, the immediate reward is not concerned with the timing of rewards; it reflects the instantaneous consequence of an action in a given state.

Set of States(S)
S represents the collection of all possible states that the system (or agent) can be in.
States are the different situations or configurations that characterize the system at a specific point in time.
For example, in a grid world, each cell might be a state, and the agent moves from one cell to another.
Set of Actions
A is the set of all possible actions that the agent can take.
Actions are the decisions or moves that the agent can make in a given state to transition to a new state.
For example, in a grid world, actions could be movements like up, down, left, or right.

Markov Decision Process (MDP) is a mathematical model used in decision-making problems where an agent interacts with an environment. It's characterized by states, actions, transition probabilities, and rewards. The Markov property assumes that the future state depends only on the current state and action, not on the past sequence of states and actions.
This article offers a glimpse into the captivating world of Markov Descision Process. .Though it is not easy to add algorithms to the process so we will use jupyter notebooks next time . It will be a journey that spans the intricacies of artificial neurons, the power of hidden layers, and the transformative potential of these technologies.
-Thank You For Extreme Patience and Wonderful Time


